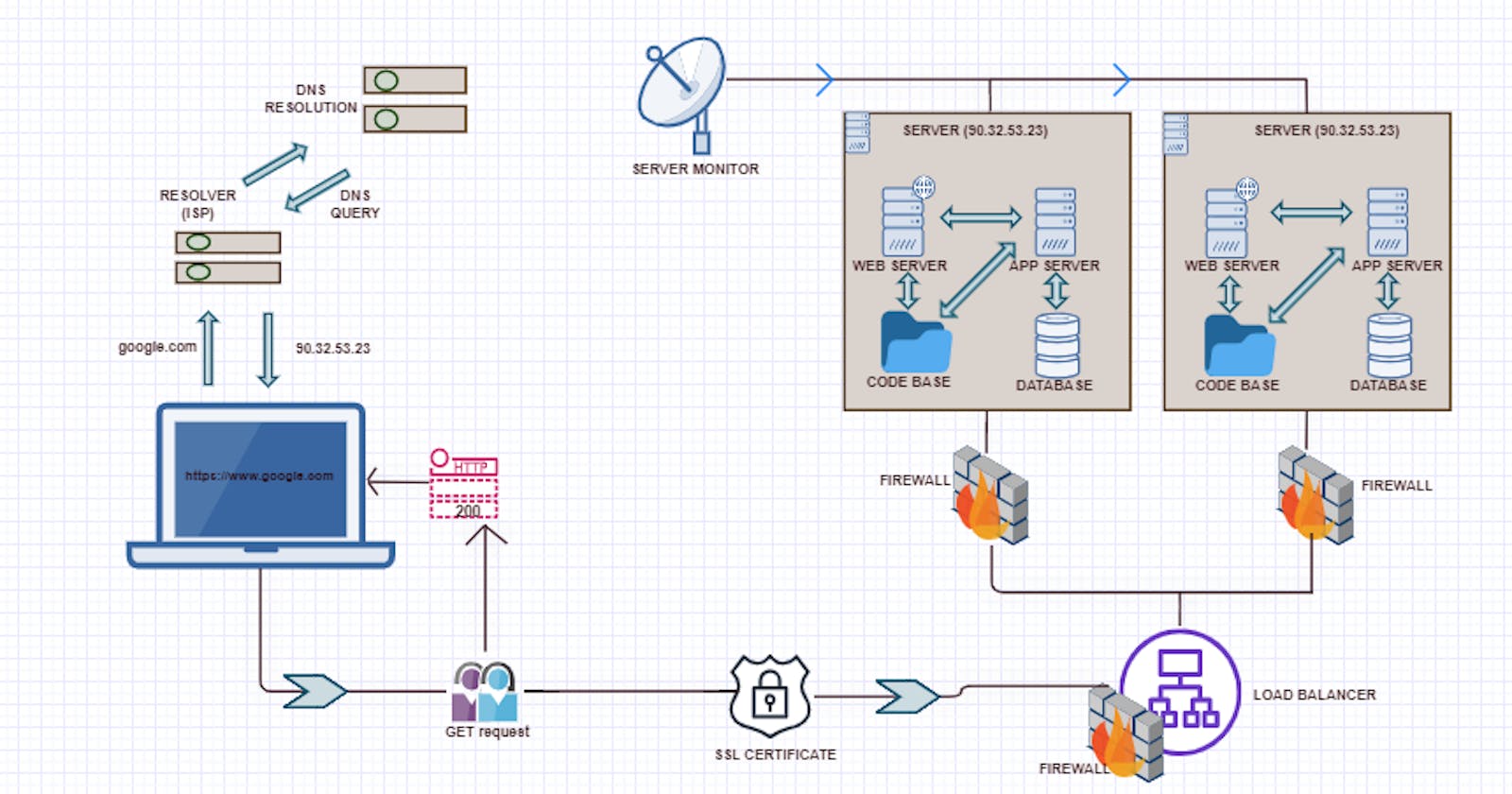
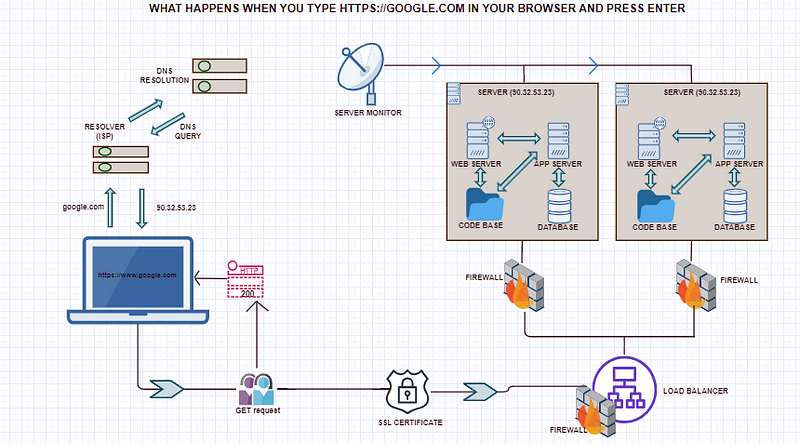
What happens when you type https://www.google.com in your browser and click enter?


INTRODUCTION
Curious isn’t it?
In today’s world, we use the internet for just about everything. From sending emails, playing games, watching movies, getting information, shopping online, and countless others, we make use of search engines to use the internet.
I have been quite puzzled about how it worked right from my teenage age and am certain you have also wondered about what happens when you enter a URL like google.com in your browser and click enter. Well, worry no more as I would give you a practical guide of what happens in the split second of you searching for a URL in your browser.
Before then, I want to walk you through the concepts behind the process and then give you a complete overview of the entire search action. I would assume you understand what a browser is, but for the sake of a beginner-friendly article, a browser is an application that a client(you) uses for accessing the web. One action done with the browser like that which we are about to discuss is requesting a webpage.
A webpage is basically a text file formatted a certain way so that your browser (ie. Chrome, Firefox, Safari, etc) can understand it; this format is called HyperText Markup Language (HTML)
CONCEPTS:
DNS request
TCP/IP
Firewall
HTTPS/SSL
Load-balancer
Web server
Application server
Database
DNS REQUEST:
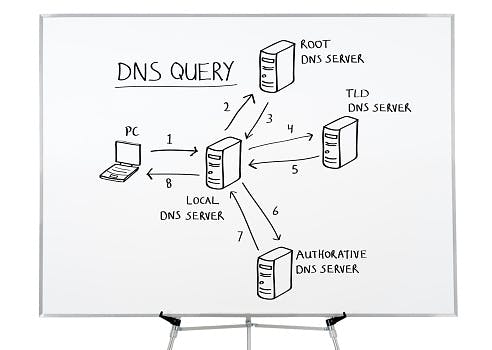
DNS stands for “Domain Name System”. It is basically a technology used for directing a text-based domain name(google.com) to its corresponding numerical-based (216.58.223.238) IP address. The Internet Protocol(IP) address is formatted in an hexa decimal way e.g. 97.32.43.54 which is not easily memorized by humans but rather by machines. DNS helps humans easily memorize domains and maps them to the desired IP address. This is done through a DNS request.
When a user enters a URL and clicks Enter, the browser must first determine the IP address of the server that is hosting the webpage. This is achieved by using a DNS query, also known as a DNS request, in which the user’s computer (a DNS client) requests a DNS server’s response with the IP address for the domain name (a computer server that contains a database of public IP addresses and their associated hostnames.).When an IP address is still unknown, it first checks the browser and/or OS cache before moving on to the Resolver server, which is often your Internet service provider. All resolvers are required to know where to find the Root Servers(this sits at the top of the DNS hierarchy), which in turn knows where to find the ‘.COM’ TLD (Top-Level Domain) server. Some other Top-Level Domains are .ORG, .NET. In the event that the resolver is unable to discover https://www.google.com, the root server informs it of where to find the ‘.COM’ TLD server. In order to avoid having to query the root server again and making another journey, the resolver first caches this information. When contacted by the ‘.COM’ TLD server, the server, if it is unaware of the IP address, offers the authoritative name servers for google.com. Once more, the resolver saves this fresh data. The final authority in charge of processing requests of this kind is the authoritative name server. After obtaining the IP address and saving it, the resolver returns home to provide the OS with this data.
TCP/IP:
TCP (Transmission Control Protocol) and IP (Internet Protocol) are two of the main networking protocols that make up the Internet. They work together to establish a connection between a client and a server and facilitate the transmission of data between them. Ensuring data is sent and received over computers irrespective of their different infrastructure.
TCP/IP is a set of guidelines for internet-connected computer systems that are conceived in layers. The layers are listed below:
Application layer: This is where applications like your browser communicate directly. This layer includes protocols such as HTTP (for viewing websites) and SMTP (for checking email). The Application layer receives data from the browser and sends it to the second layer through a port.
Transport Layer: TCP and a second scheme called UDP are both present in the Transport Layer, which is the second layer. In order for TCP to understand where the data is coming from, each application layer protocol utilizes a separate port to interact with this layer. Once the data has been received by TCP, it divides it into smaller units known as segments, commonly referred to as packets, so that each one may travel the shortest distance possible. TCP appends a header to each segment that contains instructions on what order to reassemble the segments into as well as error-checking information so that the computer can determine whether the segments arrived without any problems in order to reunite them properly when they reach their destination. The segments are then put onto the third layer after this is complete.
Internet Layer: The third layer, the Internet Layer, receives the segments and appends the origin and destination IP addresses to each segment so that regardless of the path the segments may travel, they are aware of their origin and destination. After that, the segments are sent to the top layer.
Network Access Layer. Also known as the Datalink layer. Data transmission between two devices connected to the same network is handled by it. It specifies how the data should be physically sent across the network.
At this point, your computer essentially just says, “Hey, I need the content of https://www.google.com," using the “HTTPS” language, and the server on the IP answers with the web pages based on the agreed-upon language.
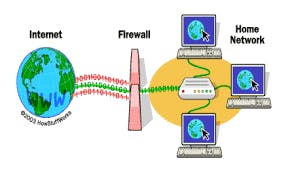
FIREWALL:
A firewall is a security system that monitors and controls incoming and outgoing network traffic based on predetermined security rules. Its primary purpose is to protect a network from external threats, such as hackers and malware.
When you type a URL like “google.com” into your browser, the request that your browser makes to Google’s server passes through the firewall on its way. The firewall checks the incoming request to make sure it is allowed based on its security rules.
There are two main types of security rules that a firewall uses to check incoming requests:
Rules that allow or block traffic based on the source and destination of the request. For example, a firewall may be configured to block all traffic from certain countries or to allow only certain IP addresses to access the network.
Rules that allow or block traffic based on the type of traffic. For example, a firewall may be configured to block all traffic on certain ports (such as those used by malware) or to allow only certain types of traffic (such as HTTP or HTTPS).
If the incoming request meets the security rules set by the firewall in front of Google’s server, it is allowed through, and the browser is able to access the website.
However, if the request does not meet the security rules, it is blocked, and the browser is unable to access the website.
HTTPS/SSL:
HTTPS (Hypertext Transfer Protocol Secure) is a secure version of the HTTP protocol used to transmit data on the Internet. It is used to encrypt the data transmitted between your browser and Google’s server.
SSL (Secure Sockets Layer) and TLS (Transport Layer Security) are encryption protocols that are used to secure the data transmitted over HTTPS.
When your browser establishes a connection with Google’s server using HTTPS, your browser and Google’s server first agree on the version of SSL/TLS to use and then create a secure, encrypted channel for transmitting the data. This process is known as a “Handshake”

LOAD BALANCER:
A load balancer is a device that distributes incoming network traffic across a group of servers or resources.
Its primary function is to ensure that the traffic is distributed evenly across the servers in order to avoid overloading any single server and to increase the overall capacity and reliability of the system.
Most top web companies like Google, LinkedIn, Facebook, and Twitter that have huge traffic do not have one server but rather tens of thousands that receive requests. The web traffic is distributed to these servers with the help of a Load Balancer using an algorithm.
There are two types of Load Balancer:
Software Load Balancer: They are software programs that use one or more scheduling algorithms. Three basic scheduling algorithms used are Weighted Scheduling, Round Robin, and Least Connection first Scheduling. These algorithms can also be merged for a particular load balancer. Examples are Nginx, Haproxy, Varnish, and Balance.
Hardware Load Balancer: They are specialized routers or switches between clients and servers. They are implemented on Layer 4-Transport and Layer 7 — Application layer of the Operating System Interface(OSI) model. Examples are the Barracuda load balancer and Cisco system catalysts.
WEB SERVER:
A web server is a software program that is responsible for handling HTTP requests and serving web pages when a client browser requests it. It delivers web pages to browsers. The web pages can be static or dynamic web pages. It is a Static page when the web server sends the hosted files to the load balancer without updating any part of the content of the page, which in turn sends to the browser. It is a dynamic page when the web server uses application logic and functional programs from the application server to update the content of the webpage according to the browser’s request before serving it to the load balancer who in turn hands the response to the browser.

APPLICATION SERVER:
Unlike the web server, the application server is a server that controls the business logic and functions of the program through any port. It servers the logic/functions to the web server instructing it on how to update the HTTP content to be served to the browser.
DATABASE:
The database is an organized collection of data, information so that it can be easily updated and managed. It is usually integrated with the application server in providing dynamic content to the web server. For example, if you are searching for a specific product on an e-commerce website, the application server may need to retrieve information about the product from a database.
Once the application server has obtained the necessary data, it sends it back to the web server, which includes it in the response that is sent back to the browser. The browser then uses this information to display the search results to you.
When you submit a search query to Google, the request is first sent to the load balancer, which forwards it to one of the web servers in the Google server network. The web server then sends the request to the application server, which processes the request and generates the search results.
Depending on the complexity of the search query, the application server may need to make a request to a database in order to retrieve the necessary data.
An Overview of what happens when you type google.com in your browser:
So back to the main question of what happens when you type google.com or any other URL (Uniform Resource Locator) in your web browser and press Enter. So the first thing that happens is that your browser looks up its cache to see if that website was visited before and if the IP address is known. If it can’t find the IP address for the URL requested then it asks your operating system to locate the website. The first place your operating system is going to check for the address of the URL you specified is in the hosts’ file (/etc/hosts in Linux and Mac, c:\windows\system32\drivers\etc\hosts in Windows). If the URL is not found inside this file, then the OS will make a DNS request to find the IP Address of the web page. The first step is to ask the Resolver (or Internet Service Provider) server to look up its cache to see if it knows the IP Address, if the Resolver does not know then it asks the root server to ask the .COM TLD (Top Level Domain) server — if your URL ends in .NET then the TLD server would be .NET and so on — the TLD server will again check in its cache to see if the requested IP Address is there. If not, then it will have at least one of the authoritative name servers associated with that URL, and after going to the Name Server, it will return the IP Address associated with your URL. All this was done in a matter of milliseconds WOW!
After the OS has the IP Address and gives it to the browser, it then makes a GET (a type of HTTP Method) to the said IP Address. When the request is made the browser again makes the request to the OS which then, in turn, packs the request in the TCP traffic protocol we discussed earlier, and it is sent to the IP Address. On its way, it is checked by both the OS’ and the server’s firewall to make sure that there are no security violations. And upon receiving the request the server (usually a load balancer that directs traffic to all available web servers for that website) sends a response with the IP Address of the chosen web server along with the SSL (Secure Sockets Layer) certificate to initiate a secure session (HTTPS). Finally, the chosen web server then sends the HTML, CSS, and Javascript files (If any) after querying the application server and database, back to the OS who in turn gives it to the browser to interpret it. And then you get your website displayed on your browser as you know it. Tadaarrh!
CONCLUSION:
In conclusion, what happens when you type google.com in your browser and press enter is a long list of processes that have been enhanced over time by a reduction in the time taken for the process to be completed in milliseconds. In a blink of an eye, the entire process is complete and you have your web page displayed on your browser. I hope I have been able to give you a bird’s eye view of the entirety of entering a URL in your browser.
This article is my submission as part of a technical writing project for the ALX Africa Software Engineering Program. If you have opinions or critics, please comment below.
Thanks